Metriche di produttività
Linee di codice (poco indicativo: stessa soluzione usando + righe è peggio)
Albrecht: punti funzione (per stimare non posso usare il codice che non ho ancora, ma la progettazione!).
Somma pesata di:
- Input/output del sistema
- Interazione dell’utente
- File usati internamente
- ecc.
- Numero delle schermate da rapprentare
- Numero di report da costruire
- Numero di moduli 3GL da sviluppare
Sono dei metodi di misura alternativi al conto delle linee
Operandi: Una variabile o una costante
Operatore: un simbolo o una combinazione che influenza il valore di uno o più operandi
Indici quali (non ricordare!):Numero di operatori (E1) e operandi (E2) distinti
Numero di occorrenze di operatori (N1) e operandi (N2)
Numero di operandi concettuali in ingresso (F1) e uscita (F2)
Concetti:
Lunghezza: N = N1 + N2Stimatore di lunghezza: N’ = E1 log E1 + E2 log E2
Volume (grandezza fisica del programma) = N * log (E1 + E2)
Stimatore di difficoltà: E1 * N2 / (2 * E2)
In realtà è un metodo che lascia abbastanza il tempo che trova
McCabe (numero ciclomatico)Deriva dalla teoria dei grafi.
Vuole trovare una base per tutte le soluzioni possibili della visita del grafo dell’applicazione. Tante più sono le soluzioni che compongono questa base tanto più alta è la complessità dell’applicazione
Il numero ciclomatico è "e – n +2" dove e è il numero degli archi, n il numero dei nodi
ManagementPlanning obiettivi da raggiungere e risorse
Organizing decidere la struttura organizzativa, le responsabilità
Staffing reclutare e formare il personale
Controlling Controllo che il progetto vada come progettato
Planning
Stimare le forze
Stimare i tempi
Stimare i costi (variabile dipendente dalle prime 2)
I costi: personale tecnico, personale di supporto (segreterie, ecc.), risorse informatiche (hw e sw), materiale di consumo, struttura (affitto, bollette)
Fattori che influenzano i costi:
Numero di istruzioni da codificare
Capacità motivazioni, coordinamento del personale
Complessità dell’applicazione
Stabilità dei requisiti
Prestazioni e qualità richieste
Strumenti di sviluppo
Stime umane
Legge di Parkinson sul lavoro
Il costo dipende dalle risorse disponibile: il lavoro si espanderà fino ad occupare tutte le risorse disponibili
Price to win
Il costo è quanto più possibile il cliente è disposto a spendere
Molto usato.
Vantaggio: spesso si ottiene il lavoro (se gara)
Svantaggio: nessuna garanzia su ciò che verrà poi fatto
Non è male se posso rivedere i requisiti dopo aver preso il lavoro
Esperti esterni
E’ una prassi
Stima per analogia
Stima personale (per progetti passati) + fattori correttivi
E’ un metodo top-down
Dati d’azienda da raccogliere:
Produttività: LineeCodice/MeseUomo
Qualità: Errori/ LineeCodice
Costo unitario: CostoTotale/ LineeCodice
Oppure posso stimare sulla quantità di lavoro
Scompongo il progetto secondo una logica operativa (per fasi) e funzionale (per componenti)Quindi si stima il tempo per le singole fasi
Ancora bottom-up
Sistemi automatizzati:
Machine learning: Reti neurali, analogie, fuzzy logic
Boehm: simile a machine learning, ma si basa solo sul passato
Modello COCOMO
Tre modelli di formule
Base: dipende solo dalla stima delle linee di codice
Intermedio: 15 fattori correttivi legati a caratteristiche del progetto (legati al personale, alle macchine, legati al progetto), possibilità stima per componenti
Avanzato: non analizziamo

 Problema: "e i cicli?"
Problema: "e i cicli?"



 o (output)
o (output)  Il vettore m (marcatura)
Il vettore m (marcatura)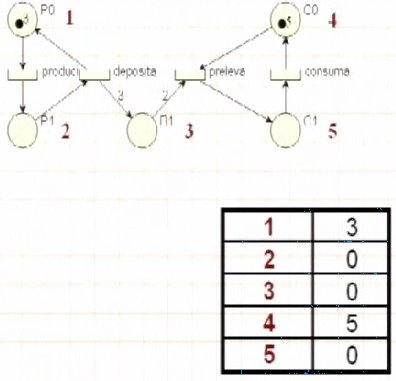 Vettore Marcatura dopo scatto di transizione:
Vettore Marcatura dopo scatto di transizione: